2025年春节期间Deepseek(以下或简称DS)可谓是火遍了全球,国内、国外下载和使用Deepseek的用户均创造记录。

那么Deepseek为什么如此火爆呢?它是凭借什么能够霸网霸屏的呢?这里说的火爆,不是指为什么成功,而是为什么如此“成功”。究其原因,主要有三个。
一、低成本震惊海内外AI领域
Deepseek的成本低的优势,不仅表现在训练成本上,更体现在它的调用成本上。

1. 训练成本低
DS架构方面:采用MoE混合专家架构等,并且创新算法,以提高计算效率。DS硬件方面:选择了H800 GPU,并进行内存优化。Deepseek的数据策略高效,使用少量的数据和参数可以达到同样的效果。
2. 调用成本低
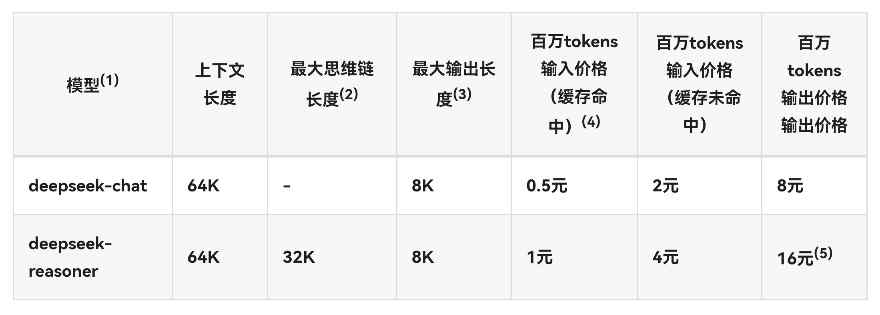
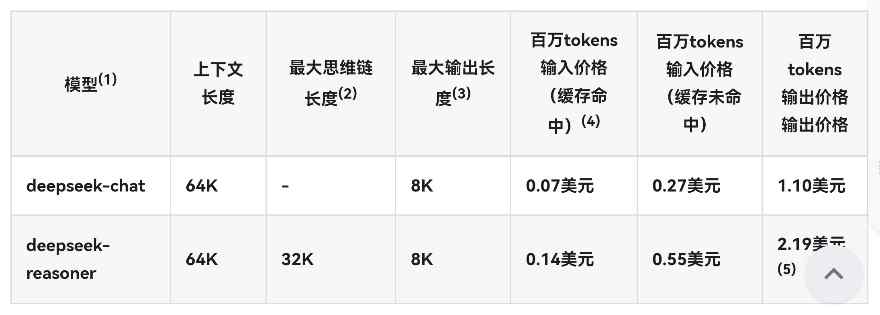
Deepseek的调用成本,相比海外的ChatGPT和国内的多家大模型厂商,具有明显的竞争力。DS调用输入tokens成本仅为ChatGPT的百分之一,输出tokens成本也是对方的几十分之一。DS的调用成本相比国内的豆包等也有明显的优势。
二、完全开源,不惧怕被抄袭
DeepSeek对全球完全开源,基于成本低的优势,可以秒杀众多大模型。

Deepseek开源能够汇聚全球优秀开发者的力量,加速模型的技术迭代;可以降低研发与使用成本,推动AI在不同行业应用落地;大大的提升DS品牌影响力,更容易建立AI大模型行业标准;代码公开,增强开发者和用户的信任;另外,DS还能促进大模型跨平台集成,吸引软件和硬件伙伴共建生态。
三、训练不依赖特定的GPU芯片
DeepSeek放弃英伟达护城河CUDA框架,采用底层的PTX编程,实现了高效且灵活。

Deepseek能对GPU硬件资源细粒度控制,可以挖掘硬件的潜力,提高运算推理的效率。
另外,Deepseek实现对非英伟达GPU的支持,包括国产GPU芯片等。其采用可扩展混合专家系统等创新架构,异构计算的感知框架,自动适配不同芯片,降低了对特定GPU芯片的依赖。







